警告
本文最后更新于 2023-12-24,文中内容可能已过时。
手动实现线程池
参考教程:Java 中的线程池是怎样实现的?
线程池的基本逻辑是创建多个线程,然后复用,复用逻辑很简单粗暴:如果任务没执行完,thread 就不会消失。即使任务执行完了,我也要造成一种假象,让 CPU 觉得还没执行完,即阻塞线程!总结一下线程池复用线程的核心逻辑:持续执行任务即使任务执行结束,也可以通过阻塞线程,不让线程结束,最终提为“线程复用”.
简单版本的线程池
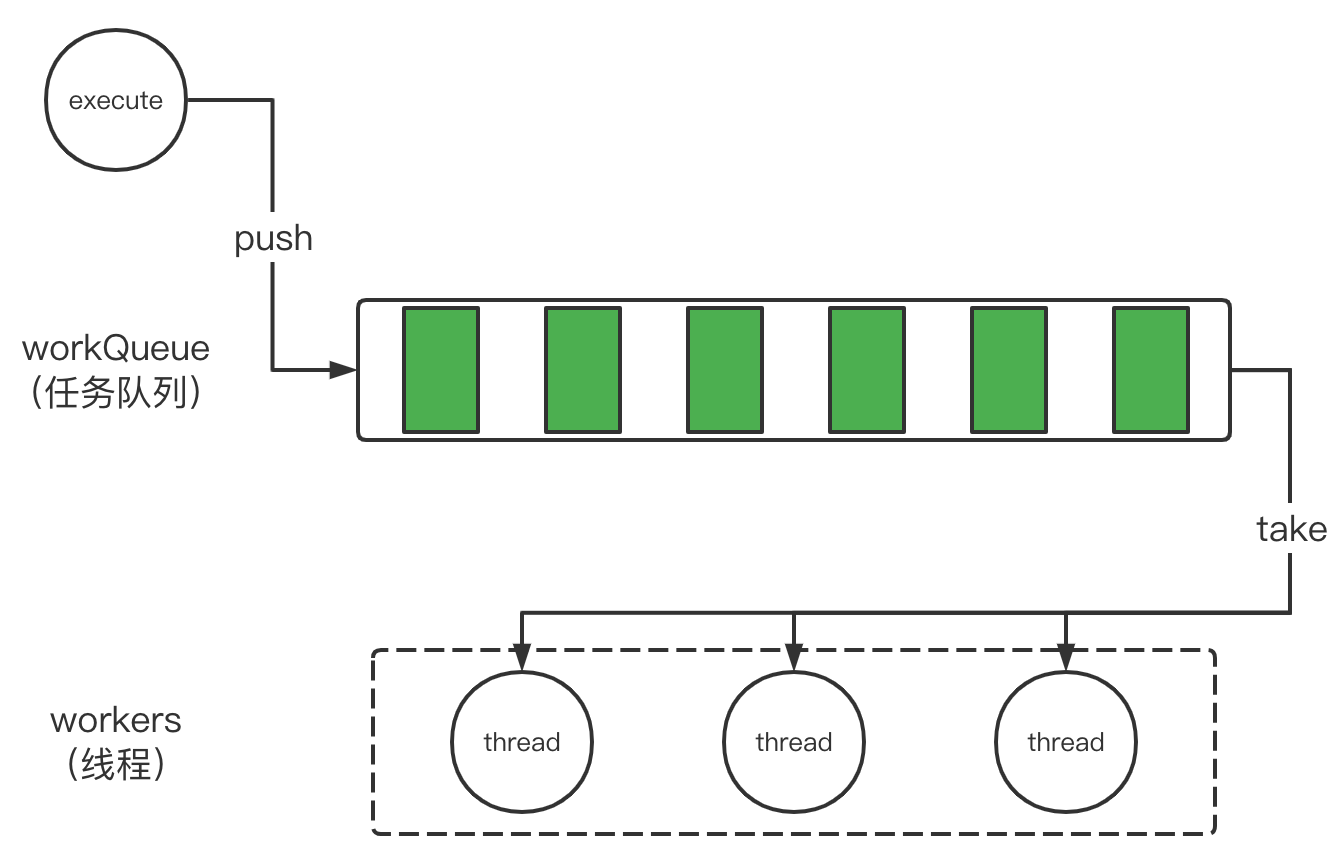
代码实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
|
public class SimpleThreadPool {
/**
* 任务队列
*/
BlockingQueue<Runnable> workQueue;
/**
* 工作线程
*/
List<Worker> workers = new ArrayList<>();
/**
* 构造器
*
* @param poolSize 线程数
* @param workQueue 任务队列
*/
SimpleThreadPool(int poolSize, BlockingQueue<Runnable> workQueue) {
this.workQueue = workQueue;
// 创建线程,并加入线程池
for (int i = 0; i < poolSize; i++) {
Worker work = new Worker();
work.start();
workers.add(work);
}
}
/**
* 提交任务
*
* @param command
*/
void execute(Runnable command) {
try {
// 任务队列满了则阻塞
workQueue.put(command);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
/**
* 工作线程,负责执行任务
*/
class Worker extends Thread {
public void run() {
// 循环获取任务,如果任务为空则阻塞等待
while (true) {
try {
Runnable task = workQueue.take();
task.run();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public static void main(String[] args) {
BlockingQueue<Runnable> workQueue = new LinkedBlockingQueue<>();
// 初始的时候就开始阻塞等待任务添加了
SimpleThreadPool simpleThreadPool = new SimpleThreadPool(3, workQueue);
for (int i = 0; i < 10; i++) {
int finalI = i;
workQueue.add(() -> {
try {
System.out.println("Starting worker " + finalI);
Thread.sleep(1000);
System.out.println("work " + finalI + " finished");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
}
}
}
|
输出,因为多线程执行的时候是无序的,因此每一次执行的输出顺序可能都不一样
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
Starting worker 0
Starting worker 2
Starting worker 1
work 1 finished
work 0 finished
Starting worker 4
work 2 finished
Starting worker 5
Starting worker 3
work 3 finished
Starting worker 6
work 5 finished
Starting worker 7
work 4 finished
Starting worker 8
work 6 finished
Starting worker 9
work 7 finished
work 8 finished
work 9 finished
|
复杂版线程池
实际的线程池实现,也差不多是这个逻辑

概念上有一点需要注意,只有核心线程数的概念,没有核心线程、未非核心线程的概念,线程池的工作过程是:当工作线程数大于核心线程数的时候,那每一个工作线程都可能会被正常关闭,随着工作任务的逐渐完成,总有那么些工作线程会正常结束,当工作线程的个数回落到小于等于核心线程数的时候,剩下的线程不会被自然释放,而是阻塞着等待工作任务的添加,在这个过程中,其实并没有哪个线程从创建开始就被打上一个核心标记然后从线程池开始到关闭都不会被回收。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
|
public class MyThreadPool {
private final ReentrantLock mainLock = new ReentrantLock();
/**
* 工作线程
*/
private final List<Worker> workers = new ArrayList<>();
/**
* 任务队列
*/
private BlockingQueue<Runnable> workQueue;
/**
* 核心线程数
*/
private final int corePoolSize;
/**
* 最大线程数
*/
private final int maximumPoolSize;
/**
* 非核心线程最大空闲时间(否则销毁线程)
*/
private final long keepAliveTime;
public MyThreadPool(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit timeUnit,
BlockingQueue<Runnable> workQueue) {
this.workQueue = workQueue;
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.keepAliveTime = timeUnit.toNanos(keepAliveTime);
}
public void execute(Runnable task) {
if (task == null) {
throw new IllegalArgumentException("Task cannot be null");
}
//1. 核心线程数未到达上限的时候,创建核心线程处理任务
if (workers.size() < corePoolSize) {
this.addWorker(task, true);
return;
}
// 2. 核心线程数已到达上限,但是任务队列未满的时候,尝试直接加入任务队列
boolean enqueued = workQueue.offer(task);
if (enqueued) {
return;
}
// 3. 核心线程数已到达上限,任务队列已满,创建非核心线程处理任务
if (!this.addWorker(task, false)) {
// 4. 核心线程数已到达上限,任务队列已满,非核心线程数达到上限,触发拒绝策略
// throw new RuntimeException("拒绝策略");
System.out.println("线程池处理能力已达上限,无法执行任务!");
}
}
private boolean addWorker(Runnable task, boolean core) {
int wc = workers.size();
if (wc >= (core ? corePoolSize : maximumPoolSize)) {
return false;
}
boolean workerStarted = false;
try {
Worker worker = new Worker(task);
final Thread thread = worker.getThread();
if (thread != null) {
// 添加任务的时候,因为 workers 不是线程安全的,因此需要加锁
mainLock.lock();
workers.add(worker);
thread.start();
workerStarted = true;
}
} catch (Exception e) {
e.printStackTrace();
} finally {
mainLock.unlock();
}
return workerStarted;
}
private void runWorker(Worker worker) {
Runnable task = worker.getTask();
try {
// 循环处理任务
while (task != null || (task = getTask()) != null) {
// Worker 首先执行自身初始化的时候绑定的任务,然后再去队列里获取任务来执行
task.run();
task = null;
}
} finally {
// getTask() 方法告诉我们,从循环退出来,意味着当前,工作线程数是大于核心线程数的,因此当前线程完成工作之后,且在规定时间之内没有获取新的任务,需要被销毁
// Java 的线程,既可以指代 Thread 对象,也可以指代 JVM 线程,一个 Thread 对象绑定一个 JVM 线程
// 因此,线程的销毁分为两个维度:1.把 Thread 对象从 workers 移除 2.JVM 线程执行完当前任务,会自然销毁
// 跟前面这里前后应该加锁,否则线程不安全
mainLock.lock();
try {
workers.remove(worker);
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
mainLock.unlock();
}
}
}
private Runnable getTask() {
boolean timedOut = false;
// 循环获取任务
for (; ; ) {
// 是否需要检测超时:当前线程数超过核心线程
boolean timed = workers.size() > corePoolSize;
// 需要检测超时 && 已经超时了
if (timed && timedOut) {
return null;
}
try {
// 是否需要检测超时
// 1.需要:poll 阻塞获取,等待 keepAliveTime,等待结束就返回,不管有没有获取到任务
// 2.不需要:take 持续阻塞,直到获取结果
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
private class Worker implements Runnable {
private Thread thread;
private Runnable task;
public Worker(Runnable task) {
this.task = task;
thread = new Thread(this);
}
@Override
public void run() {
runWorker(this);
}
public Thread getThread() {
return thread;
}
public void setThread(Thread thread) {
this.thread = thread;
}
public Runnable getTask() {
return task;
}
public void setTask(Runnable task) {
this.task = task;
}
}
public static void main(String[] args) {
// 注意,需要指定阻塞队列的长度,LinkedBlockingQueue 的默认长度是 Integer.MAX_VALUE,相当于没有限制,也就是说可以无限添加任务,这可能会造成内存溢出
MyThreadPool threadPool = new MyThreadPool(3, 5, 500, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<>(3));
for (int i = 0; i < 10; i++) {
int finalI = i;
threadPool.execute(() -> {
try {
System.out.println("Starting worker " + finalI);
Thread.sleep(1000);
System.out.println("work " + finalI + " finished");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
}
}
}
|
执行输出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
线程池处理能力已达上限,无法执行任务!
线程池处理能力已达上限,无法执行任务!
Starting worker 6
Starting worker 2
Starting worker 0
Starting worker 1
Starting worker 7
work 2 finished
Starting worker 3
work 7 finished
Starting worker 4
work 0 finished
Starting worker 5
work 1 finished
work 6 finished
work 3 finished
work 5 finished
work 4 finished
|
可以注意到,有两个任务在添加到线程池的时候被拒绝了,因为线程池的参数处理不了这么多任务的并发。
还有一点需要注意,初始化线程池的时候,需要指定阻塞队列的长度,LinkedBlockingQueue 的默认长度是 Integer.MAX_VALUE,相当于没有限制,也就是说可以无限添加任务,这可能会造成内存溢出。
JDK 的线程池实现类 - ThreadPoolExecutor
JDK 中我们最常用的线程池实现为ThreadPoolExecutor,其实上面一个小节中,我们手动实现的复杂版线程池MyThreadPool就是已经差不多实现了ThreadPoolExecutor的大部分功能了,执行流程还有思路都是一样的,
ThreadPoolExecutor的任务调度机制:
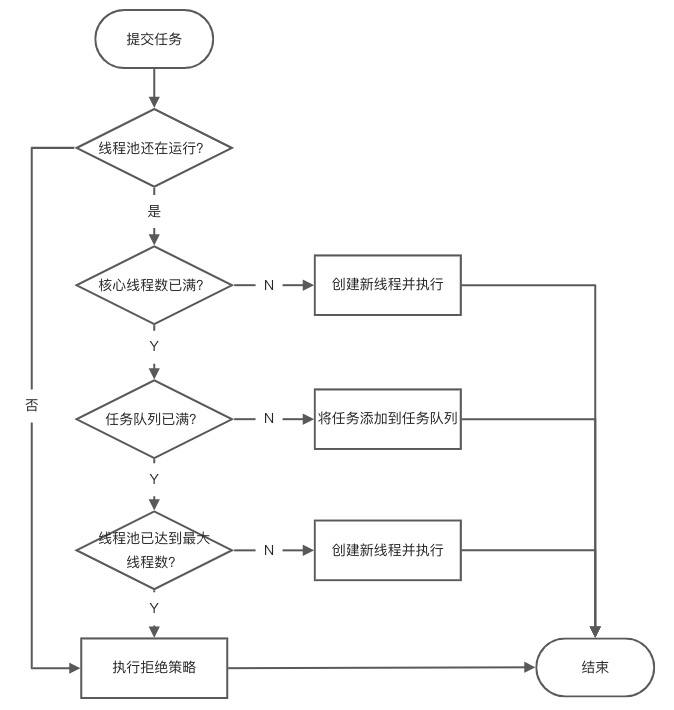
ThreadPoolExecutor线程池有如下几种状态:
-
RUNNING:运行状态,接受新任务,持续处理任务队列里的任务;
-
SHUTDOWN:不再接受新任务,但要处理任务队列里的任务;
-
STOP:不再接受新任务,不再处理任务队列里的任务,中断正在进行中的任务;
-
TIDYING:表示线程池正在停止运作,中止所有任务,销毁所有工作线程,当线程池执行terminated()方法时进入TIDYING状态;
-
TERMINATED:表示线程池已停止运作,所有工作线程已被销毁,所有任务已被清空或执行完毕,terminated()方法执行完成;
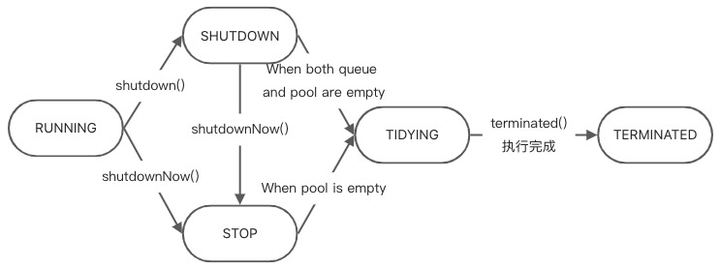
我们应该这样优雅地关闭线程池:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
public void destroy() {
try {
poolExecutor.shutdown();
if (!poolExecutor.awaitTermination(AWAIT_TIMEOUT, TimeUnit.SECONDS)) {
poolExecutor.shutdownNow();
}
} catch (InterruptedException e) {
// 如果当前线程被中断,重新取消所有任务
pool.shutdownNow();
// 保持中断状态
Thread.currentThread().interrupt();
}
}
|
为了实现优雅停机的目标,我们应当先调用shutdown方法,调用这个方法也就意味着,这个线程池不会再接收任何新的任务,但是已经提交的任务还会继续执行。之后我们还应当调用awaitTermination方法,这个方法可以设定线程池在关闭之前的最大超时时间,如果在超时时间结束之前线程池能够正常关闭则会返回 true,否则,超时会返回 false。通常我们需要根据业务场景预估一个合理的超时时间,然后调用该方法。
如果awaitTermination方法返回 false,但又希望尽可能在线程池关闭之后再做其他资源回收工作,可以考虑再调用一下shutdownNow方法,此时队列中所有尚未被处理的任务都会被丢弃,同时会设置线程池中每个线程的中断标志位。shutdownNow并不保证一定可以让正在运行的线程停止工作,除非提交给线程的任务能够正确响应中断。
ThreadPoolExecutor甚至跟MyThreadPool的参数都是差不多的。
1
2
3
4
5
6
7
|
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
|
这里重点说一下MyThreadPool中没有说明的参数
workQueue 参数:
在构造函数中,workQueue 表示任务队列,线程池任务队列的常用实现类有:
-
ArrayBlockingQueue :一个数组实现的有界阻塞队列,此队列按照 FIFO 的原则对元素进行排序,支持公平访问队列。
-
LinkedBlockingQueue :一个由链表结构组成的可选有界阻塞队列,如果不指定大小,则使用Integer.MAX_VALUE作为队列大小,按照 FIFO 的原则对元素进行排序。
-
PriorityBlockingQueue :一个支持优先级排序的无界阻塞队列,默认情况下采用自然顺序排列,也可以指定Comparator。
-
DelayQueue:一个支持延时获取元素的无界阻塞队列,创建元素时可以指定多久以后才能从队列中获取当前元素,常用于缓存系统设计与定时任务调度等。
-
SynchronousQueue:一个不存储元素的阻塞队列。存入操作必须等待获取操作,反之亦然。
-
LinkedTransferQueue:一个由链表结构组成的无界阻塞队列,与LinkedBlockingQueue相比多了transfer和tryTranfer方法,该方法在有消费者等待接收元素时会立即将元素传递给消费者。
-
LinkedBlockingDeque:一个由链表结构组成的双端阻塞队列,可以从队列的两端插入和删除元素。
threadFactory 参数:
在构造函数中,threadFactory 表示线程工厂。用于指定为线程池创建新线程的方式,threadFactory 可以设置线程名称、线程组、优先级等参数。如通过 Guava 工具包可以设置线程池里的线程名:
1
|
new ThreadFactoryBuilder().setNameFormat("general-detail-batch-%d").build()
|
handler 参数,这个参数表示拒绝策略
在构造函数中,rejectedExecutionHandler 表示拒绝策略。当达到最大线程数且队列任务已满时需要执行的拒绝策略,常见的拒绝策略如下:
-
ThreadPoolExecutor.AbortPolicy:默认策略,当任务队列满时抛出 RejectedExecutionException 异常。
-
ThreadPoolExecutor.DiscardPolicy:丢弃掉不能执行的新任务,不抛任何异常。
-
ThreadPoolExecutor.CallerRunsPolicy:当任务队列满时使用调用者的线程直接执行该任务。
-
ThreadPoolExecutor.DiscardOldestPolicy:当任务队列满时丢弃阻塞队列头部的任务(即最老的任务),然后添加当前任务。
基于ThreadPoolExecutor和其支持的参数,我们可以定制化一些满足特定需求的线程池,比如自定义拒绝策略,比如定期执行特定的任务,或者固定线程的数量,不存在非核心线程数,其实 JDK 中已经提供了这些定制化的的线程池。比如定期执行线程池由ScheduledThreadPoolExecutor实现(去看定时调度线程池),而且线程池还提供了Executors工具类(去看JDK 线程池工具类小节),除此之外,一些第三方的 Java 工具包比如 Guava 等也会自带一些线程池(去看第三方 Java 工具类小节),
简单分析一下ThreadPoolExecutor的继承结构
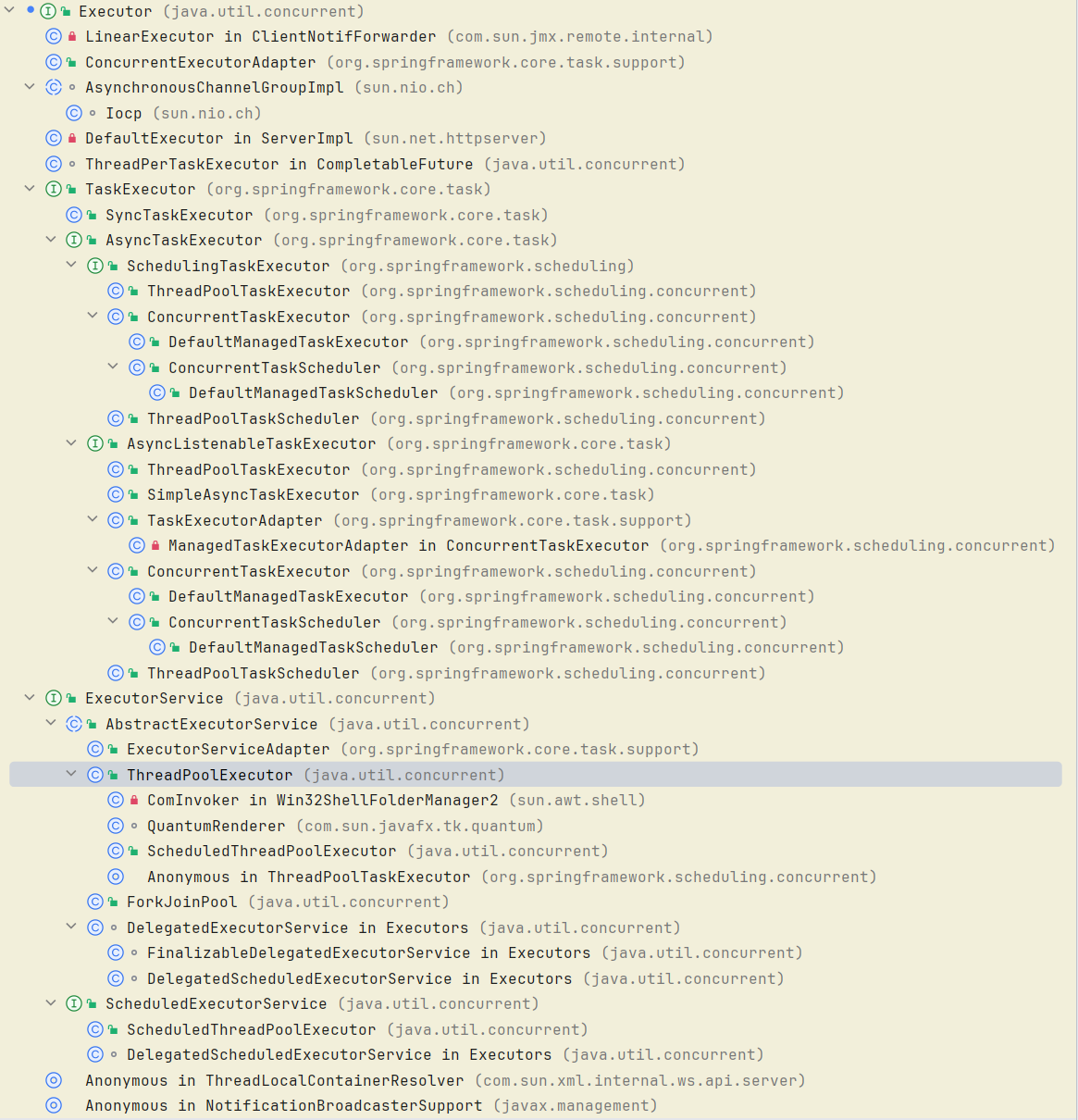
顶级接口为Executor,ExecutorService继承了Executor,然后抽象类AbstractExecutorService继承ExecutorService,最终,线程池类ThreadPoolExecutor再继承AbstractExecutorService。另外ScheduledThreadPoolExecutor实际上继承了ThreadPoolExecutor。
此外我们还看到ForkJoinPool跟线程池类ThreadPoolExecutor一样继承AbstractExecutorService。当我们像通过多个线程来完成任务的时候,如果通过水平拆分即可完成任务,那用普通的线程池即可,如果需要分层级拆分然后向上汇总,那就用ForkJoinPool。这个我们在《Fork-Join 框架》中深入学习过ForkJoinPool,这是一个分治算法的多线程实现类。
定时调度线程池 - ScheduledThreadPoolExecutor
ScheduledThreadPoolExecutor实际上继承了ThreadPoolExecutor,从代码中可以看出,ScheduledThreadPool基于ThreadPoolExecutor,corePoolSize大小为传入的corePoolSize,maximumPoolSize大小为Integer.MAX_VALUE,超时时间为 0,workQueue 为DelayedWorkQueue。实际上ScheduledThreadPool是一个任务调度线程池,通过实现ScheduledExecutorService来获取定时调度的能力,主要实现了三种调度方式:
-
ScheduledExecutorService#schedule:延迟指定时间的执行一次性操作
-
ScheduledExecutorService#scheduleAtFixedRate:延迟指定时间之后按照固定的的周期执行任务,即第一个任务的触发时间为initialDelay,第二个人物的触发时间为initialDelay+period,第三个任务的触发时间为initialDelay+period*2,以此类推,如果前一个任务报错了,那么后一个任务就不会再执行。
-
ScheduledExecutorService#scheduleWithFixedDelay:延迟指定时间之后按照固定的延时执行任务,什么叫固定延时,就是前一个任务执行完之后等一个固定的时间,再执行第二次,如果有一次执行报错,后面的任务都不会再执行
简单实践如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
public static void main(String[] args) {
ScheduledExecutorService executorService = Executors.newScheduledThreadPool(10);
executorService.schedule(() -> {
System.out.println(Thread.currentThread().getName());
System.out.println("延时一次性任务");
}, 1, TimeUnit.SECONDS);
executorService.scheduleAtFixedRate(() -> {
System.out.println(Thread.currentThread().getName());
System.out.println("延时周期性任务");
}, 1,1, TimeUnit.SECONDS);
executorService.scheduleWithFixedDelay(() -> {
System.out.println(Thread.currentThread().getName());
System.out.println("延时固定延时任务");
}, 1,1, TimeUnit.SECONDS);
}
|
输出
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
pool-1-thread-2
pool-1-thread-3
pool-1-thread-1
延时一次性任务
延时固定延时任务
延时周期性任务
pool-1-thread-1
延时周期性任务
pool-1-thread-3
延时固定延时任务
pool-1-thread-2
延时周期性任务
pool-1-thread-4
延时固定延时任务
pool-1-thread-5
延时周期性任务
pool-1-thread-1
延时固定延时任务
pool-1-thread-6
延时周期性任务
|
因为会一直输出,后续输出省略
JDK 线程池工具类 - Executors
线程池还提供了Executors工具类,通过其中的静态方法,可以快速构建线程池,比如
-
Executors#newSingleThreadExecutor:创建只有一个线程的线程池,SingleThreadExecutor适用于串行执行任务的场景,每个任务按顺序执行,不需要并发执行;
-
Executors#newFixedThreadPool:创建用于固定线程个事而且全都是核心线程的线程池,FiexedThreadPool适用于负载略重但任务不是特别多的场景,为了合理利用资源,需要限制线程数量;
-
Executors#newCachedThreadPool:创建一个按需创建线程的线程池,如果没有任务要处理,则不保留任何线程,核心线程数为 0,最大线程数不能超过Integer.MAX_VALUE,相当于没有限制,可能会内存溢出,调用 execute 将重用以前构造的线程(如果线程可用)。如果没有可用的线程,则创建一个新线程并添加到线程池中。终止并从缓存中移除那些已有 60 秒钟未被使用的线程。CachedThreadPool适用于并发执行大量短期耗时短的任务,或者负载较轻的服务器;
-
Executors#newSingleThreadScheduledExecutor:创建只有一个线程的定时线程池
-
Executors#newScheduledThreadPool:创建固定数量的定时线程池
-
Executors#defaultThreadFactory:创建默认的线程工厂
但是要注意,Executors 类看起来功能比较强大、用起来还比较方便,但存在如下弊端:
-
newFixedThreadPool和newSingleThreadExecutor任务队列长度为Integer.MAX_VALUE,可能会堆积大量的请求,从而导致 OOM;
-
newCachedThreadPool和newScheduledThreadPool允许创建的线程数量为Integer.MAX_VALUE,可能会创建大量的线程,从而导致 OOM;
那如何避免呢?
除此之外还有这些注意点
使用线程时,可以直接调用 ThreadPoolExecutor的构造函数来创建线程池,并根据业务实际场景来设置corePoolSize、blockingQueue、RejectedExecuteHandler等参数。
增加异常处理,为了更好地发现、分析和解决问题,建议在使用多线程时增加对异常的处理,异常处理通常有下述方案:
第三方 Java 工具类
Guava
Guava 等也会自带一些线程池,比如
ListeningExecutorService:这个线程池主要是对现有的线程池进行包装,添加了线程事件的监听机制,生成方法为MoreExecutors.listeningDecorator。
ListeningExecutorService
简单实践如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
public static void main(String[] args) throws InterruptedException {
int threadCount = 5;
CountDownLatch latch = new CountDownLatch(threadCount);
// 创建一个线程缓冲池 Service
ExecutorService executor = Executors.newCachedThreadPool();
// 创建一个 ListeningExecutorService 实例
ListeningExecutorService executorService = MoreExecutors.listeningDecorator(executor);
for (int i = 0; i < threadCount; i++) {
// 提交一个可监听的线程 (可以返回自定义对象,也可直接返回 String)
ListenableFuture<String> futureResult = executorService.submit(() -> {
System.out.println(Thread.currentThread().getName());
// throw new Exception("测试异常 Exception)");
return "success";
});
// 对结果进行监听,如果不指定线程池,则默认使用的是 MoreExecutors.sameThreadExecutor() 线程池
Futures.addCallback(futureResult, new FutureCallback<String>() {
@Override
public void onSuccess(@Nullable String result) {
System.out.println("执行成功,返回结果:" + result);
latch.countDown();
}
@Override
public void onFailure(Throwable t) {
System.out.println("执行失败,返回结果:" + t.getMessage());
}
}, executor);
}
// 线程执行完毕之后,关掉线程池
latch.await();
executorService.shutdown();
}
|
输出
1
2
3
4
5
6
7
8
9
10
|
pool-1-thread-1
pool-1-thread-2
执行成功,返回结果:success
pool-1-thread-1
pool-1-thread-3
执行成功,返回结果:success
执行成功,返回结果:success
执行成功,返回结果:success
pool-1-thread-5
执行成功,返回结果:success
|
因为我们使用的是Executors.newCachedThreadPool构造线程池,因此并不会创建 5 个线程,实际创建了 4 个线程,存在一种情况是提交一个新任务的时候,之前创建的线程已经执行完任务,已经空闲,此时这个线程会继续从任务列表里拿任务执行,而不会创建新的线程,如果此时所有线程都没有执行完任务,没有空闲的线程,才会创建新的线程来执行任务。
这里有一点需要注意,Futures.addCallback有一个不需要指定线程池的版本
1
2
3
4
|
public static <V> void addCallback(ListenableFuture<V> future, FutureCallback<? super V> callback) {
// 默认选择当前线程池
addCallback(future, callback, MoreExecutors.sameThreadExecutor());
}
|
这个方法默认采用了SameThreadExecutorService线程池,这个线程池的特点是,会在调用execute/submit方法的线程也就是提交任务的线程执行每个任务,也就是说,使用这个线程池执行任务不是异步的,是同步的,任务将顺序执行
跟这个ThreadPoolExecutor.CallerRunsPolicy拒绝策略很像,这个策略会在线程池满了的时候,将任务放到提交任务到线程池的操作所在的线程执行
简单测试一下:
1
2
3
4
5
6
7
8
9
10
11
|
public static void main(String[] args) {
ListeningExecutorService sameExecutor = MoreExecutors.sameThreadExecutor();
for (int i = 0; i < 10; i++) {
int finalI = i;
sameExecutor.submit(() -> {
String name = Thread.currentThread().getName();
System.out.println("当前线程名称为:" + name + " 顺序为:" + finalI + " ");
});
}
System.out.println("任务执行完成");
}
|
输出:
1
2
3
4
5
6
7
8
9
10
11
|
当前线程名称为:main 顺序为:0
当前线程名称为:main 顺序为:1
当前线程名称为:main 顺序为:2
当前线程名称为:main 顺序为:3
当前线程名称为:main 顺序为:4
当前线程名称为:main 顺序为:5
当前线程名称为:main 顺序为:6
当前线程名称为:main 顺序为:7
当前线程名称为:main 顺序为:8
当前线程名称为:main 顺序为:9
任务执行完成
|
可以看到所有任务都是在main线程执行,而且任务执行完成是在最后输出的,也就是说不仅submit方法提交的多个任务之间是顺序执行的,submit方法提交的任务和main线程之间也是同步的。
因此,当我们往ListeningExecutorService里提交一个任务,并在返回的ListenableFuture上添加回调(Futures.addCallback)的时候,这个回调函数实际上会在ListeningExecutorService分配出来执行这个任务的线程上继续执行,也就是 task 和 callback 会在同一个线程上执行,而且是阻塞的,这会导致线程被长期占用,不利于充分发挥线程池的性能,因此,Guava 建议手动指定线程池。以免阻塞当前线程池:
1
|
Futures.addCallback(futureTask,callback,executorService);
|
这个带线程池参数的版本的实际内容如下,也很简单
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
public static <V> void addCallback(final ListenableFuture<V> future, final FutureCallback<? super V> callback, Executor executor) {
Preconditions.checkNotNull(callback);
Runnable callbackListener = new Runnable() {
@Override
public void run() {
final V value;
// 只监听 onFailure 和 onSuccess
try {
// TODO(user): (Before Guava release), validate that this
// is the thing for IE.
value = getUninterruptibly(future);
} catch (ExecutionException e) {
callback.onFailure(e.getCause());
return;
} catch (RuntimeException e) {
callback.onFailure(e);
return;
} catch (Error e) {
callback.onFailure(e);
return;
}
callback.onSuccess(value);
}
};
// 最终还是调用 ListenableFuture 自身的 addListener 方法
future.addListener(callbackListener, executor);
}
|
我们还可以将多个 ListenableFuture 合并成一个 ListenableFuture,多个ListenableFuture全部完成,合并出来的ListenableFuture才会完成,实践如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
public static void main(String[] args) {
ExecutorService executor = Executors.newCachedThreadPool();
// 创建一个 ListeningExecutorService 实例
ListeningExecutorService executorService = MoreExecutors.listeningDecorator(executor);
// 测试多个 futureResult 合并
List<ListenableFuture<String>> futureResults = new ArrayList<ListenableFuture<String>>();
for (int i = 0; i < 5; i++) {
// 提交一个可监听的线程 (可以返回自定义对象,也可直接返回 String)
int finalI = i;
ListenableFuture<String> futureResult = executorService.submit(() -> String.valueOf(finalI));
futureResults.add(futureResult);
}
//将多个 ListenableFuture 的合并成一个 ListenableFuture,
// 当所有 Future 成功时返回多个 Future 返回值组成的 List 对象。
// 其中一个 Future 失败或者取消的时候,将会进入失败或者取消。
final ListenableFuture allFutures = Futures.allAsList(futureResults);
final ListenableFuture transform = Futures.transform(allFutures, new AsyncFunction<List<String>, String>() {
/**
* 用给定的输入封装一个特定的 ListenableFuture 作为输出
*
* @param input
*/
@Override
public ListenableFuture<String> apply(@Nullable List<String> input) {
// List<String> 中保留的是每个 futureResults 中每个 ListenableFuture 任务的结果
// 这里可以对 input 进行复杂的处理,返回最终的一个结果 比如:对团单详情,团单优惠,团单使用范围进行组装
// Futures.immediateFuture 的作用是返回一个立即填充返回值的 ListenableFuture
return Futures.immediateFuture(StringUtils.join(input, ";"));
}
}, executor);
Futures.addCallback(transform, new FutureCallback<String>() {
@Override
public void onSuccess(@Nullable String result) {
System.out.println("执行成功,返回结果:" + result);
// 记得关闭线程池
executorService.shutdown();
}
@Override
public void onFailure(Throwable t) {
System.out.println("执行失败,返回结果:" + t.getMessage());
}
}, executor);
}
|
输出
其实 JDK 中自带的CompletableFuture就可以实现ListenableFuture合并的效果,多个CompletableFuture并行执行,且全部完成了之后,合并出来的CompletableFuture才会完成,简单实践如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
/**
* CompletableFuture 的写法
* 代码更少,写起来更快,但是没有监听功能
*/
public static void main(String[] args) throws ExecutionException, InterruptedException {
int futureCount = 5;
List<CompletableFuture<String>> allFutures = new ArrayList<>();
for (int i = 0; i < futureCount; i++) {
int finalI = i;
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> String.valueOf(finalI));
allFutures.add(future);
}
// 将其进行组合
CompletableFuture<Void> voidCompletableFuture = CompletableFuture.allOf(allFutures.toArray(new CompletableFuture[0]));
voidCompletableFuture.get();
System.out.println("获取结果");
for (int i = 0; i < futureCount; i++) {
System.out.println(allFutures.get(i).join());
}
}
|
输出
1
2
3
4
5
6
|
获取结果
0
1
2
3
4
|

 小虾米
小虾米