
Linux 文件系统基础
 小虾米
小虾米Linux 文件系统基础
很多文件处理命令都是以一行为单位进行处理
RLF、HRLF
LF、RLF、HRLF 控制字符:
-
LF:换行符 Line Feed
-
RLF:逆向换行符 Reverse/Retrorse Line Feed:ESC-7(escape then 7)
-
HRLF:半逆向换行符 Half Reverse Line Feed:ESC-8 (escape then 8)
顾名思义,换行符使得光标到达下一行的开头,逆向换行符会使得光标回到上一行的开头,半逆向换行符会使得光标回到上一行,但是不会到达开头。
其中,LF 值得一讲,在 Windows 平台、Mac OS 和 Linux 平台。有所不同
-
CR(Carriage Return):用符号
\r表示,十进制 ASCII 代码是 13,十六进制 代码为0x0D; -
LF(Line Feed):使用
\n符号表示,ASCII 代码是 10, 十六制为0x0A。
在 window 中:
-
\r:回车,回到当前行的行首,而不会换到下一行,如果接着输出的话,本行以前的内容会被逐一覆盖; -
\n:换行,换到当前位置的下一行,而不会回到行首;
所以 Windows 上的另起一行重新输入就是\r\n
在 Linux 中,
\n:回车 + 换行,即回到当前行的行首,然后换到下一行;
所以 Linux 上的另起一行重新输入就是\n
在 MacOS 中
\r:回车 + 换行,即回到当前行的行首,然后换到下一行;
文件描述符
文件描述符经常缩写为 fd。
Linux 系统中,把一切都看做是文件,当进程打开现有文件或创建新文件时,内核向进程返回一个文件描述符,文件描述符就是内核为了高效管理已被打开的文件所创建的索引,用来指向被打开的文件(说白了也就是指针),所有执行 I/O 操作的系统调用都会通过文件描述符。
linux 启动后,会默认打开 3 个文件描述符,分别是:标准输入 standard input 0,正确输出 standard output 1,错误输出:error output 2
文件描述符、文件、进程间的关系:
-
每个文件描述符会与一个打开的文件相对应
-
不同的文件描述符也可能指向同一个文件
-
相同的文件可以被不同的进程打开,也可以在同一个进程被多次打开
系统为维护文件描述符,建立了三个表
-
进程级的文件描述符表
-
系统级的文件描述符表
-
文件系统的
i-node表
有资源的地方就有战争,“文件描述符"也是一种资源,系统中的每个进程都需要有"文件描述符"才能进行改变世界的宏图霸业。世界需要秩序,于是就有了"文件描述符限制"的规定。简而言之就是每个进程拥有的文件描述符的数量是有限的,达到限制就会出现"Too many open files” 的提示,可以通过增大进程可用的文件描述符数量来解决,但往往故事不会这样结束,很多时候,并不是因为进程可用的文件描述符过少,而是因为程序 bug,打开了大量的文件链接(注意,web 连接也会占用文件描述符)而没有释放。程序申请的资源在用完后及时释放,才是解决"Too many open files"的根本之道。
我们可以自定义文件描述符
|
|
&[n]代表是已经存在的文件描述符,&1 代表输出 &2 代表错误输出,&-代表关闭与它绑定的描述符
简单的例子:
$ exec 4< input.txt:使用文件描述符 4 打开并读取文件
$ exec 5>input .txt:创建一个文件描述符用于写入(截断模式),打开文件用于写入
$ exec 6 >>input .txt:创建一个文件描述符用于写入(追加模式)
exec 6>&-:接触文件描述符 6 的绑定,创建的文件描述符用完之后要接触绑定,不然会报 Too many open files 的错。
ls /proc/self/fd/:查看所有的文件描述符,此命令默认会输出0 1 2 3,3 代表什么?# What is the file descriptor 3 assigned by default?>
我的理解是,3 是临时的浏览的文件的描述符,比如 ls,就需要用到 3,你浏览 A 文件,A 文件就是 3,你浏览 B 文件,B 文件就是 3,就是这样。为什么是 3,因为 3 是第一个可用的文件描述符,012 都已经被占用了。
0,1,2,3 就是指针,指向特定的文件而已。
标准输入/标准输出/标准错误
系统预留了三个文件描述符,分别是 0,1,2,他们的意义分别有如下对应关系:
-
0:stdin(标准输入)

执行 read 的时候,敲击键盘输入的 1111 2222 就是标准输入
-
1:stdout(标准输出)

红框中的那么多内容,就是标准输出。其他命令比如
find命令执行之后,也会列出一大堆字符,这些字符就是标准输出 -
2:stderr(标准错误)

红框中的那一段错误信息,就是标准错误。
严格来说,以上表述都不是很准确,0,1,2 都是文件描述符,其指代的是文件,stdin、stdout、stderr 也都是文件,所以红框中的内容,其实也是 stdin、stdout、stderr 对应的文件的内容
标准输入(stdin)和参数输入
在 Bash 中,标准输入(stdin)和参数输入有一些不同之处。
标准输入是指从键盘或其他输入设备接收数据的过程。当你在终端输入命令时,你可以通过键盘输入数据,并将其作为标准输入传递给命令。
参数输入是指通过命令行参数传递给脚本或命令的数据。你可以在执行命令时,通过在命令后面添加参数来传递数据。这些参数可以是文件名、选项、标志或其他需要的数据。
区别在于:
-
标准输入是实时输入的过程,你可以逐行输入数据。参数输入是在执行命令时一次性传递的数据。
-
标准输入通常用于需要与用户交互的命令或程序,而参数输入通常用于将数据传递给脚本或命令进行处理。
-
标准输入可以通过重定向从文件中读取数据,而参数输入只能通过命令行参数传递。
xargs可以将管道或标准输入(stdin)数据转换成命令行参数。
常规方式下,我们可以通过管道符将一个命令的标准输出直接作为另一个命令的标准输入,如果命令不接受标准输入,我们可以通过$()将其包装成一个命令行参数来传递
那怎么判断一个命令是否能接受标准输入呢?如果命令能够让终端阻塞,说明该命令接收标准输入,反之就是不接受,比如你只运行cat命令不加任何参数,终端就会阻塞,等待你输入字符串并回显相同的字符串。
| 管道符号
命令执行顺序控制
通常情况下,我们在终端只能执行一条命令,然后按下回车执行,那么如何执行多条命令呢?
-
顺序执行多条命令:
command1;command2;command3;简单的顺序指令可以通过
;来实现 -
有条件的执行多条命令:
which command1 && command2 || command3-
&&:如果前一条命令执行成功则执行下一条命令,如果command1执行成功(返回 0),则执行command2 -
||:与&&命令相反,执行不成功时执行这个命令 -
$?:存储上一次命令的返回结果
-
管道命令
管道是一种通信机制,通常用于进程间的通信(也可通过 socket 进行网络通信),它表现出来的形式将前面每一个进程的标准输出(stdout)直接作为下一个进程的标准输入(stdin)。

管道命令使用 | 作为界定符号,管道命令与上面说的连续执行命令不一样。
-
管道命令仅能处理 standard output,对于 standard error output 会予以忽略。
-
less,more,head,tail…都是可以接受 standard input 的命令,所以他们是管道命令。ls,cp,mv 并不会接受 standard input 的命令,所以他们就不是管道命令了。
-
哪些命令可以接受 stdin 呢?哪些不能呢?我们在
标准输入(stdin)和参数输入小节讲过判断方法。
-
-
管道命令必须要能够接受来自前一个命令的数据成为 standard input 继续处理才行。
- 不是所有的都支持 stdin。不支持的用 xargs 命令来实现。关于 xargs 命令请看《xargs eXtended ARGuments》
为什么用管道和管道的本质
管道,英文为 pipe。这是一个我们在学习 Linux 命令行的时候就会引入的一个很重要的概念。它的发明人是道格拉斯。麦克罗伊,这位也是 UNIX 上早期 shell 的发明人。他在发明了 shell 之后,发现系统操作执行命令的时候,经常有需求要将一个程序的输出交给另一个程序进行处理,这种操作可以使用输入输出重定向加文件搞定,ls -l /etc/ > etc.txt 然后,wc -l etc.txt,但是这样未免显得太麻烦了。所以,管道的概念应运而生。目前在任何一个 shell 中,都可以使用|连接两个命令,shell 会将前后两个进程的输入输出用一个管道相连,以便达到进程间通信的目的:ls -l /etc/ | wc -l。
对比以上两种方法,我们也可以理解为,管道本质上就是一个文件,前面的进程以写方式打开文件,后面的进程以读方式打开。这样前面写完后面读,于是就实现了通信。实际上管道的设计也是遵循 UNIX 的"一切皆文件"设计原则的,它本质上就是一个文件。Linux 系统直接把管道实现成了一种文件系统,借助 VFS 给应用程序提供操作接口。虽然实现形态上是文件,但是管道本身并不占用磁盘或者其他外部存储的空间。在 Linux 的实现上,它占用的是内存空间。所以,Linux 上的管道就是一个操作方式为文件的内存缓冲区。
之前,一直不知道管道中传递内容的是什么,现在我知道了,不对接管道的时候命令输出的是什么,后面接管道的时候,其传到管道中的就是什么,"|“后面的命令会一行一行地读取前面命令的输出
管道进行搜索的时候,配合grep最好用。排序用sort最好用。
Linux 上的管道分两种类型:
-
匿名管道
- 即”|",只能在父子进程中使用,除了父子进程外,没人知道这个管道文件的描述符,所以通过这个管道中的信息无法传递给其他进程。这保证了传输数据的安全性,当然也降低了管道了通用性
-
命名管道
- 通过
mkfifo pipe或者mknod pipe创建(让人想起了mkdir),这跟创建一个文件没有什么区别。看到创建出来的文件类型比较特殊,是 p 类型(find -type参数的类型中就有 p 管道类型)。表示这是一个管道文件。有了这个管道文件,系统中就有了对一个管道的全局名称,于是任何两个不相关的进程都可以通过这个管道文件进行通信了。这里就不再细细研究。TODO
- 通过
常用命令
find -name '*.txt' | xargs -i rm {}:删除当前目录下及子目录下所有后缀为 txt 的文件
> 指令和 >> 指令
大多数 UNIX 系统命令从你的终端接受输入并将所产生的输出发送回到您的终端。
一个命令通常从一个叫标准输入的地方读取输入,默认情况下,这恰好是你的终端。同样,一个命令通常将其输出写入到标准输出,默认情况下,这也是你的终端。
重定向命令列表如下:
| 命令 | 说明 |
|---|---|
command > file |
将输出重定向到 file,如果 file 不存在,会自动创建,如果存在,会覆盖 file 的内容 |
command >> file |
将输出以追加的方式重定向到 file,如果 file 不存在,会自动创建 |
command < file |
将输入重定向到 file,如果 file 不存在,会报错 |
<< tag |
将开始标记 tag 和结束标记 tag 之间的内容作为输入,即 Here 文档 |
command 2>file |
将错误输出重定向到 file,如果 file 不存在,会自动创建 |
command 2>>file |
将错误输出以追加的方式重定向到 file,如果 file 不存在,会自动创建 |
n > file |
将文件描述符为 n 的文件重定向到 file(比如上面的 2>file) |
n >> file |
将文件描述符为 n 的文件以追加的方式重定向到 file(比如上面的 2>>file) |
n >& m |
将输出文件 m 和 n 合并,将 n 追加到 m 后面 |
n <& m |
将输入文件 m 和 n 合并 |
注意:
-
shell 遇到
>操作符,会判断右边文件是否存在,如果存在就先删除,并且创建新文件。不存在直接创建。无论左边命令执行是否成功。右边文件都会变为空。<同理。 -
>>操作符,判断右边文件,如果不存在,先创建。以添加方式打开文件,会分配一个文件描述符[不特别指定,默认为 1,2]然后,与左边的标准输出(1)或错误输出(2)绑定。 -
当命令执行完,绑定文件的描述符也自动失效。0,1,2 又会空闲。
-
一条命令启动,命令的输入,正确输出,错误输出,默认分别绑定 0,1,2 文件描述符。
-
一条命令在执行前,先会检查输出是否正确,如果输出设备错误,将不会进行命令执行
应用:
command > file、command < file、command >> file都很好理解,
我们还可以这样:
command1 < infile > outfile:同时替换输入和输出,执行 command1,从文件 infile 读取内容,然后将输出写入到 outfile 中。
command 2>file 和 command 2>>file 也很好理解
我们可以将 stdout 和 stderr 合并后重定向到 file,可以这样写:
command > file 2>&1 或者 command >> file 2>&1:先将标准输出重定向到 file 下,然后再将错误输出合并到标准输出
也可以写成command >& file,只不过这样写无法追加
放在>后面的&,表示重定向的目标不是一个文件,而是一个文件描述符,而 &> file 是一种特殊的用法,也可以写成 >& file。
&> 或者 >& 视作整体,分开没有单独的含义
> file 可用于直接清空文件内容
临时重定向和永久重定向
输出重定向有两种方式临时重定向和永久重定向。对于临时重定向,可以使用 > 或者 >> 符号。如果您有很多数据需要重定向,则可以使用 exec 命令进行永久重定向。这个命令我们在前文也了解过。
永久重定向并不是真的就一直唯一类型的重定向,可以随时使用exec命令进行修改。永久重定向相当于为进程创建一个文件描述符,接下来运行命令的标准输出,标准错误,标准输入都使用同一文件描述符。例如
exec 1> $log_file_path
此命令将会重定向 exec命令之后的所有标准输出,比如 echo 生成的标准输出。如果运行 cat 命令查看 $log_file_path 对应的文件,我们将看到 echo 命令的标准输出。则个命令可用于记录所有命令输出到日志文件中。
Here Document
Here Document 是 Shell 中的一种特殊的重定向方式,用来将输入重定向到一个交互式 Shell 脚本或程序。它的基本的形式如下:
|
|
它的作用是将两个 delimiter 之间的内容 (document) 作为输入传递给 command。delimiter 可以为任意字符
很简单:
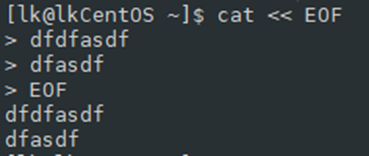
<< 这两个连续小于符号,他代表的是『结束的输入字符』的意思。这样当空行输入 eof 字符,输入自动结束,不用Ctrl+D,只要输入了 <<,再输入一段字符(tag),再按回车就会出现 >,让你输入内容,最后再输出一遍 tag 表示结束。tag 可与为任何内容。

/dev/null文件
如果希望执行某个命令,但又不希望在屏幕上显示输出结果,那么可以将输出重定向到 /dev/null,比如command > /dev/null
/dev/null是一个特殊的文件,写入到它的内容都会被丢弃;如果尝试从该文件读取内容,那么什么也读不到。但是/dev/null文件非常有用,将命令的输出重定向到它,会起到"禁止输出“的效果。
如果希望屏蔽 stdout 和 stderr,可以这样写:command > /dev/null 2>&1

cat /dev/null > file_name:清空文件
管道命令与重定向区别
区别是:
- 对管道来说,左边的命令应该有标准输出
|右边的命令应该接受标准输入。但是对于重定向,左边的命令应该有标准输出>右边只能是文件,或者左边的命令应该需要标准输入<右边只能是文件
2、管道触发两个子进程执行|两边的程序;而重定向是在一个进程内执行