
Netdata 系统监控工具
 小虾米
小虾米Netdata 系统监控工具
作为一个监控系统而言,Netdata 简单好上手,确实很不赖
参考信息
部署架构
Netdata 可用于监控各种基础设施,从独立的微型物联网设备到结合内部部署和云基础设施的复杂混合设置,混合裸机服务器,虚拟机和容器。
Netdata 生态系统有 3 个组成部分:
-
Netdata Agents,用于监控基础设施的物理或虚拟节点,包括在其上运行的所有应用程序和容器。
-
Netdata Parents,在您的基础设施中创建数据集中点,在您的生产系统中分担 Netdata Agents 的功能,提供数据的高可用性,增加数据保留时间和进行节点隔离。Netdata Parents 是通过 Netdata Agent 软件实现的。任何 Netdata Agent 都可以同时是一个节点的 Agent 和其他代理的 Parent。建议设置多个 Netdata Parent。它们都将通过 Netdata Cloud 无缝地集成到一个监控解决方案中。
-
Netdata Cloud,Netdata 官方提供的 SaaS(得加钱),将您所有的基础设施,所有 Netdata Agent 和 Netdata Parent,整合到一个统一的、分布式的、可扩展的监控数据库中,提供先进的数据切片和切割功能,自定义仪表板,先进的故障排除工具,用户管理,集中式警报管理等。
Netdata Agent 是一款高度模块化的软件,通过众多插件、内部自带的时间序列数据库、查询引擎、健康监测和警报、机器学习和异常检测和将指标导出到第三方系统,来提供数据收集。尤其是这个指标导出到第三方系统,可以与我们自己的指标监控系统集成。
三种部署架构:
-
独立部署 Netdata Agent。为了帮助我们的用户在第一次安装 Netdata 时获得完整的体验,具有默认配置的 Netdata Agent 是一个开箱即用的完整监控解决方案,这些默认配置都是默认启用的,并且可以直接使用。一般我们用的最多的就是这种方式。
此外,如果你想在一个面板下看到多个节点的信息,同时又懒得配置 Netdata Parents,你可以使用 Netdata Cloud,通过将每个 Agent 连接到 Cloud,您可以看到所有节点的概览,包括聚合图表和集中警报,而无需设置父节点。
-
多个 Netdata Agent + 一个 Netdata Parent。连接到 Netdata Parent 节点的 Netdata Agent 称为 Child 节点。它将把指标流传递给它的父节点。然后,父节点可以负责代表该节点存储指标(保留时间更长),处理显示仪表板的指标查询,并提供警报。
这样,就可以将 Child Netdata Agent 配置为在 RAM 中而不是在磁盘上保留数据(保留时间更短),并禁用警报和其他功能。因为这些工作都可以让 Netdata Parent 节点来做。
这种设置允许更精简的子节点,并且非常适合具有多个节点的情况。如果子节点暂时不可用或退役,指标数据仍然可以访问,尽管在父节点不可用的情况下没有故障转移。如果要求有故障转移,那就得上双活了。
-
多个 Netdata Agent + 两个 Netdata Parent(双活父节点),为了获得高可用性,可以将 Netdata Parent 配置为,在 Netdata Parent 之间传递每个的 Netdata Parent 节点接收到的 Netdata Agent 传过来的数据,以保持多个 Netdata Parent 之间的数据的同步(每个 Netdata Parent 节点都拥有所有的 Netdata Agent 的数据)。每个 Netdata Agent(子代理)配置了两个 Netdata Parent(父代理)的地址,但一次只会将数据传递到到其中一个父代理。当该父节点不可用时,子代理将重新连接到另一个。当之前挂掉的父节点再次可用时,这个父节点将通过接收来自第二个父节点的数据同步到所有的 Netdata Agent 的数据。
其实一般情况下,我们独立部署即可。需要进行集群监控的时候,才会需要使用多个 Netdata Agent + 一个 Netdata Parent 方案或者多个 Netdata Agent + 两个 Netdata Parent 方案。
时序数据库引擎
DBENGINE 是 Netdata 的时序数据库。相关设计。
独立部署 Netdata Agent
其他部署方式后面用到再学习
安装 Netdata Agent
在线
https://learn.netdata.cloud/docs/installing/one-line-installer-for-all-linux-systems
一键安装
|
|
netdata-kickstart.sh的各项参数:
我们会经常用到这个脚本
离线
官方文档:offline-systems
官方文档中虽然提供了离线安装教程,但是,官方提供的脚本会从 Github 下载安装包,这对国内的网络环境来说不友好,因此我们可以直接访问Releases · netdata/netdata-nightlies · GitHub来下载与当前硬件对应的包,可以直接下载.gz.run结尾的包,
netdata-nightlies这个仓库会将主仓库netdata每隔几天就打包发布一次,以提供最新的安装包
Linux 系统下的
.run文件跟 Windows 系统下的.exe文件类似,是一个可执行的程序。一般用于制作安装包,关于如何制作.run文件,请参考:Linux 制作 run 格式安装包
run 安装包的使用方式如下:
- 打开终端并导航到
xxx.run文件所在的目录。 - 运行以下命令来使
xxx.run文件可执行:chmod a+rwx xxx.run。 - 运行以下命令来安装
xxx.run文件:./xxx.run。
卸载 Netdata Agent
|
|
其他安装方式
-
RPM,其中,包下载地址中,先选 stable,然后再选 Linux 发行版版本,其中 el 适用于 Red Hat Enterprise Linux 和二进制兼容发行版,如 CentOS、Alma Linux 和 Rocky Linux。
-
Docker,在这个教程中提供了详细的说明,其中容器地址为netdata/netdata
启动 Netdata Agent
其实当我们在安装 Netdata Agent 时,该客户端的守护进程就已经配置好了开机自启。这对于我们在页面上连续观察重启后的指标变化非常方便。
通常,我们需要重新启动 Netdata Agent 以加载新的或正在编辑的配置文件(configuration files)。运行状况配置文件(health configuration)是唯一的例外,因为可以在不重新启动整个代理的情况下重新加载它们。
停止或重新启动 Netdata Agent 将导致存储的指标出现间隔。
通常,我们推荐通过systemctl管理 Netdata Agent:
-
通过
systemctl start netdata启动之后,访问本地的 19999 端口,即访问 http://localhost:19999/ 即可。 -
systemctl stop netdata,停止 Netdata Agent -
systemctl restart netdata,重启 Netdata Agent
随便截几张图,都是贼炫酷,确实好用又好看。
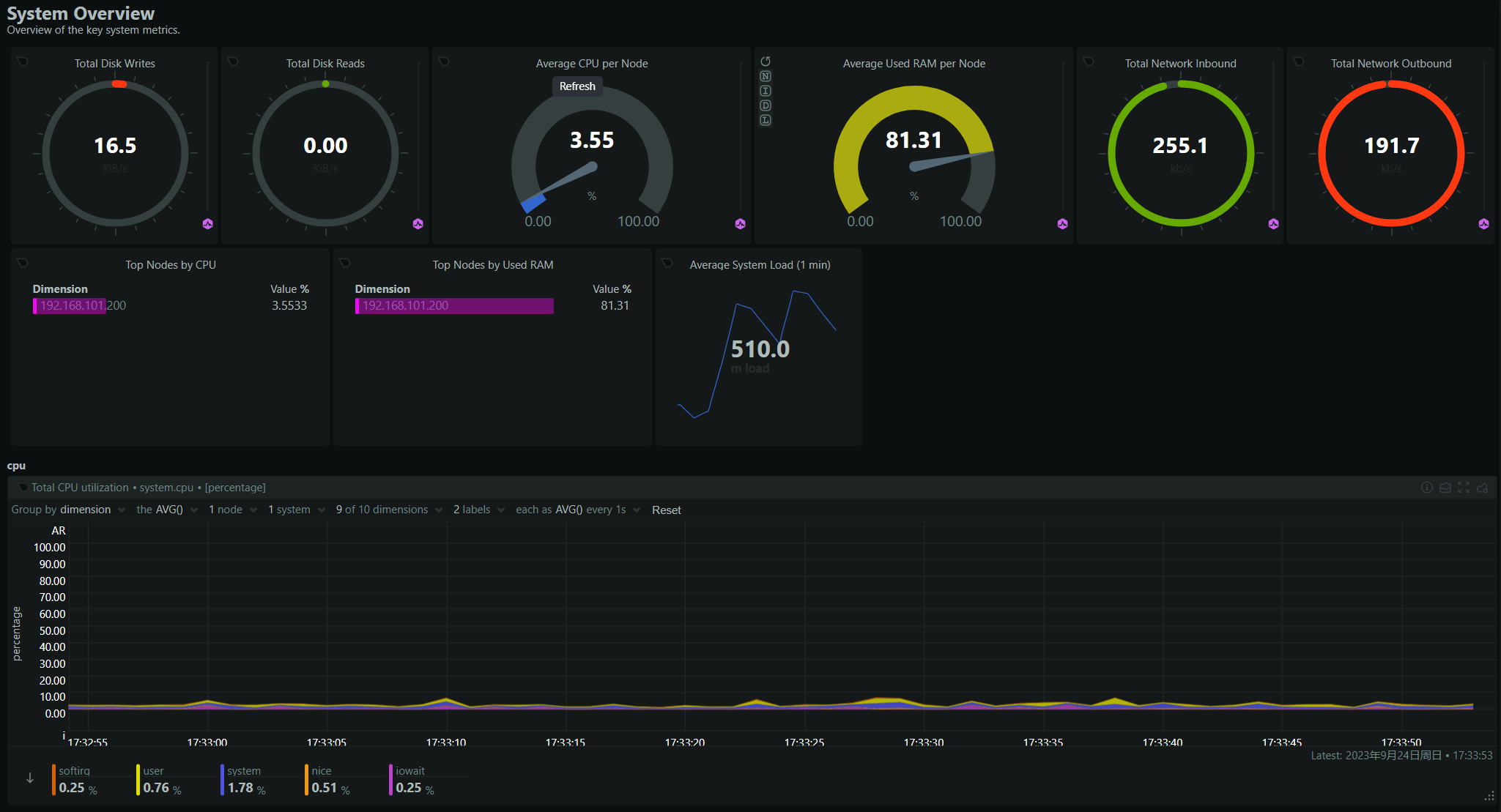
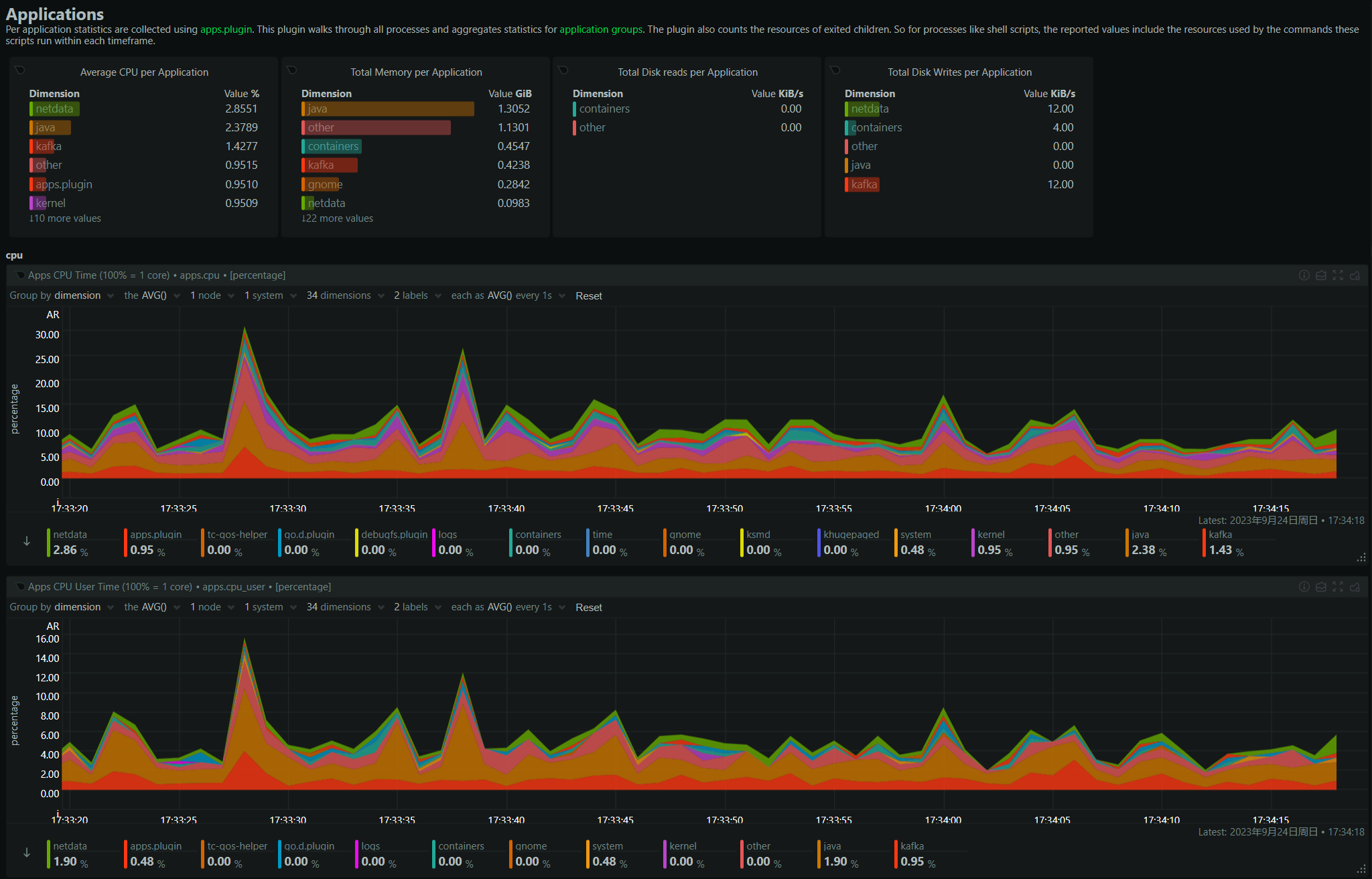
除了有 Web 页面,我们还可以通过通过 rest 接口来查询指定指标或者 netdata 的相关信息,具体 API 列表,请看 swagger 页面
配置
启动之后,通过http://localhost:19999/netdata.conf可以看到netdata的所有配置,这个链接中的内容,对应着服务器上的/etc/netdata/netdata.conf,
关于
netdata.conf的完整的默认内容,请看附录中的默认的 netdata.conf小节,官网文档的 这里,详细介绍了每一个配置项是什么意思。
配置文件所在的目录为/etc/netdata
|
|
这里 介绍了这些文件夹都是什么意思
你可以通过这个目录下的./edit-config netdata.conf工具,来编辑配置文件。
/etc/netdata/health.d目录下的文件配置了告警和通知的规则,一个文件对应一个规则,注意,修改规则之后需要重新夹在 Netdata 的健康配置
|
|
Netdata 的常用配置:
-
提高节点的安全性,包括用户注册和认证
数据收集
当 Netdata 启动时,在没有配置的情况下,它会自动检测数千个数据源,并立即按秒的频率收集的指标。Netdata 可以立即从这些端点收集指标,这要归功于 300 多个收集器,这些收集器都是在安装 Netdata 时已经预装好了的。默认情况下,每次安装 Netdata 都会安装所有收集器。您不需要手动安装收集器来从新源收集指标。这真的很赞。在启动时,只要收集器和应用程序/服务都配置正确,Netdata 将自动检测任何具有收集器的应用程序或服务。如果你看不到应用对应的图表,则需要查看 收集器配置参考手册
什么是收集器
Netdata 使用收集器来帮助您从您最喜欢的应用程序和服务中收集指标,并在实时交互式图表中查看它们。
随着我们继续努力将所有收集器迁移到 Go,一些收集器同时具有 Go 和 Python 版本。在这些情况下,Netdata 总是优先考虑 Go 版本,我们强烈建议您使用 Go 版本以获得最佳体验。如果您想使用 Python 版本的收集器,则需要显式禁用 Go 版本,并启用 Python 版本。然后 Netdata 会跳过 Go 版本,并尝试加载 Python 版本及其附带的配置文件。
当前支持的收集器
https://learn.netdata.cloud/docs/data-collection/monitor-anything
- APM:Go 应用、Java Spring Boot 2 应用(需要配置 Spring Boot Actuator),JMX等
- Authentication and Authorization:例如SSH
- Blockchain Servers
- CICD Platforms:例如Jenkins
- Cloud Provider Managed
- Containers and VMs:例如Docker、Podman、VMware
- Databases:例如Cassandra、Clickhouse、InfluxDB、MongoDB、Mysql、Redis
- Distributed Computing Systems
- DNS and DHCP Servers
- eBPF
- FreeBSD
- FTP Servers
- Gaming,甚至还可以监控游戏,我的天,例如CS:GO、Minecraft、Steam
- Generic Data Collection
- Hardware Devices and Sensors
- IoT Devices
- Kubernetes:例如Kubelet
- Linux Systems:例如CPU使用率、磁盘使用率
- Logs Servers
- macOS Systems
- Mail Servers
- Media Services
- Message Brokers:例如Kafka、RabbtMQ、MQTT
- Networking Stack and Network Interfaces
- Incident Management
- Observability
- Other
- Processes and System Services
- Provisioning Systems
- Search Engines:例如Elasticsearch
- Security Systems
- Service Discovery / Registry:例如ZooKeeper
- Storage, Mount Points and Filesystems
- Synthetic Checks
- System Clock and NTP
- Systemd
- Task Queues
- Telephony Servers
- UPS
- VPNs
- Web Servers and Web Proxies:例如Apach、Clash、HTTPD、Nginx、Tomcat
- Windows Systems
进入每一个具体类型的收集器中,我们可以看到我们可以查看到的指标,比如在APM收集器中,点击 Java Spring Boot 2 applications 进入 Java Spring Boot 2 applications 收集器页面,在 java-spring-boot-2-applications 指标 小节中可以看到所有的指标
所有的指标名称都有一个springboot2.前缀
| Metric | Scope | Dimensions | Units |
|---|---|---|---|
| response_codes | global | 1xx, 2xx, 3xx, 4xx, 5xx | requests/s |
| thread | global | daemon, total | threads |
| heap | global | free, eden, survivor, old | B |
| heap_eden | global | used, commited | B |
| heap_survivor | global | used, commited | B |
| heap_old | global | used, commited | B |
| uptime | global | uptime | seconds |
自定义指标收集器
如果在当前支持的收集器中没有找到你想要监听的应用或者服务:
-
如果你的应用提供Prometheus端点接口,Netdata也能监控它,参考generic Prometheus collector.
Prometheus端点:Prometheus endpoint,一般为一个HTTP URL,通常为
http://<ip>:<port>/metrics,提供符合Prometheus格式的指标数据,Prometheus数据库可通过访问此接口获取应用的指标数据并保存到Prometheus数据库中。generic Prometheus collector的配置方式也很简单,找到
go.d/prometheus.conf文件,一般在/etc/netdata或者/opt/netdata/etc/netdata目录下,然后在jobs节点下添加采集的应用的名称和Prometheus endpoint 地址即可,例如1 2 3jobs: - name: local url: http://127.0.0.1:9090/metrics大部分的应用,只要是提供了监控功能,基本都会兼容Prometheus,而为了兼容Prometheus,基本上都会提供Prometheus endpoint,因此,Netdata兼容这些应用主要也是通过这种方式,非常简单快捷。
像TDengine数据库,通过 taosKeeper 服务提供Prometheus endpoint,向 Prometheus提供指标
像MySQL数据库,通过MySQL Exporter提供Prometheus endpoint,向 Prometheus提供指标
-
如果您的应用配置好了,会公开StatsD指标,可通过 generic StatsD collector 采集指标
-
如果您有CSV, JSON, XML或其他流行格式的数据,可通过 generic structured data (Pandas) collector 采集
告警
Netdata Agent 是监视系统、服务和应用程序的运行状况和性能的运行状况监视器。我们与 DevOps 工程师社区、SREs 和开发人员密切合作,定义了数百个不需要任何配置就可以工作的生产可用的报警规则。
Netdata Agent 的运行状况监视系统也是动态的,完全可定制的。你可以编写全新的报警规则,也可以调整社区配置的报警规则(报警规则针对的是特定的应用/服务的指标),或者屏蔽任何你不感兴趣的内容。您甚至可以根据您的指标运行统计算法来增强复杂的查找。
配置通知
https://learn.netdata.cloud/docs/alerting/notifications/netdata-agent-notifications/
Netdata 提供了以下两种方式来让用户接收外部平台上的警报通知。这些方法可以独立工作,也可以并行工作,这意味着您可以同时启用这两种方法,向任意数量的端点发送警报通知。这两种方法都使用节点的健康告警规则来生成警报通知的内容。
Netdata Cloud 通过电子邮件提供集中式警报通知,它利用已经从连接节点流式传输到 Netdata Cloud 的健康状态信息,向启用它们的用户发送通知。
Netdata Agent 有一个通知系统,支持十多种服务,如电子邮件,Slack, PagerDuty, Twilio,亚马逊 SNS, Discord 等等。这里我们主要学习 Netdata Agent 的方式
Netdata Agent
Netdata Agent 的告警通知系统在每个节点上运行,并根据配置的端点(端点就是通知的目的地)和角色分派通知。您可以在任何一个节点上启用多个端点,并在 Netdata Cloud 中并行使用 Agent 通知和集中式警报通知。
注意:如果希望在基础结构中启用来自多个节点的通知(每个节点都运行 Netdata Agent),则必须单独配置每个节点。
支持的通知端点(通知目的地):
-
Messagebird:消息推送平台,官网,支持短信,电话,app 等,跟 Twilio 差不多,国内用的很少
-
ntfy:开源的消息推送平台,跟 Pushover 类似,但是开源免费,同时可以自己托管,不需要注册,推荐使用这个。
ntfy 的相关内容,请看《ntfy 开源的消息推送平台》
-
PushOver:Pushover,官网 是一个消息推送平台,可以给手机、桌面、浏览器发送自定义的推送消息。按照平台购买其客户端,即可享受此平台的永久推送服务。
-
SMS Server Tools 3:开源的短信网关服务:smstools3
-
Twilio,消息推送平台,官网,支持发短信打电话发邮件等等,发短信(SMS:Short Messaging Service)功能国内不可用
告警通知系统
配置文件 netdata.conf 中 script to execute on alarm 这一行定义的是出现告警的时候,调用的外部脚本,这个脚本默认是alarm-notify.sh,这个脚本的作用是:
-
发送通知给多个接收人
-
使用多个通知方法通知多种端点
-
为每个每个收件人过滤告警通知的等级,比如致命、错误、通知等等
而且此脚本也会考虑接收人的角色,使用告警配置的to行,将每个告警分配给一个或多个角色。
|
|
注意,alarm-notify.sh使用的是自己的配置文件health_alarm_notify.conf,默认的在/usr/lib/netdata/conf.d和/etc/netdata下,这两个目录下的health_alarm_notify.conf都会生效,不过默认情况下/etc/netdata下不存在health_alarm_notify.conf。
health_alarm_notify.conf文件的底部会保存每个角色对应的接收者,以及其通知方法,我们配置告警主要就是修改这个文件,配置的方法也很简单
|
|
一般建议通过 edit-config来修改health_alarm_notify.conf文件,主要配置两个方面:
-
通知方法(通知不同的端点):除电子邮件外,所有通知方法(通知不同的端点)都需要一些配置,比如通知ntfy的时候需要填写账号密码还有服务器地址和主题。
-
每个角色每个通知方法的收件人,
${DEFAULT_...}填写的就是接收人的信息,如果有多个,用空格隔开1 2 3 4 5 6role_recipients_email[sysadmin]="${DEFAULT_RECIPIENT_EMAIL}" role_recipients_pushover[sysadmin]="${DEFAULT_RECIPIENT_PUSHOVER}" role_recipients_pushbullet[sysadmin]="${DEFAULT_RECIPIENT_PUSHBULLET}" role_recipients_telegram[sysadmin]="${DEFAULT_RECIPIENT_TELEGRAM}" role_recipients_slack[sysadmin]="${DEFAULT_RECIPIENT_SLACK}" ...
你还可以测试告警通知
告警通知的全局配置项:
文档:Email
ntfy
关于 ntfy 的搭建和相关使用,请看《ntfy 开源的消息推送平台》
文档:ntfy
Netdata Cloud
暂时不学习
配置告警
https://learn.netdata.cloud/docs/alerting/health-configuration-reference
Netdata 的健康监视器是高度可配置的,支持动态阈值、滞后、警报模板等。您可以根据基础设施的拓扑结构或特定的监控需求调整任何现有报警规则,或者创建新的报警实体。
您可以将运行状况警报与 Netdata 的任何收集器(请参阅当前支持的收集器小节)结合使用,实时监视系统、容器和应用程序的运行状况。
虽然您可以在本地仪表板和 Netdata Cloud 上看到活动警报,但所有健康警报都是通过单独的 Netdata Agent 在每个节点上配置的。如果要跨基础结构部署新警报,则必须使用相同的运行状况配置文件配置每个节点。
先看配置通知,TOOD
数据导出
Netdata 允许您使用导出引擎将指标导出到外部时间序列数据库。该系统使用许多连接器来启动与 30 多个支持的数据库的连接,包括 InfluxDB、Prometheus、Graphite、ElasticSearch 等等。导出引擎以用户可配置的间隔重新采样 Netdata 的每秒数千个指标,并可以同时将指标导出到多个时间序列数据库。
根据您的需求和分配给外部时间序列数据库的资源,您可以配置导出指标的时间间隔,或者只导出带有过滤的特定图表。您还可以选择导出的指标是作为收集的、标准化的平均值,还是在配置的时间间隔内的指标值的总和/体积。
导出是 Netdata 努力与其他监控软件互操作的一个重要部分。您可以使用外部时间序列数据库进行长期指标保留、进一步分析或与其他工具(如应用程序跟踪)的关联。
用法
官方介绍 中提到的 Netdata 的用法
-
单独使用
-
从 Prometheus 端点中收集指标数据
-
将数据导出到外部的时序数据库,Netdata 可以将其每秒收集的指标数据发送到外部时间序列数据库,如 InfluxDB、Prometheus、Graphite、TimescaleDB、ElasticSearch、AWS Kinesis Data Streams、Google Cloud Pub/Sub Service 等。
-
通过 Grafana 进行指标数据可视化。一个流行的监控技术栈是 Netdata、Prometheus 和 Grafana。Netdata 作为监控的指标收集引擎,Prometheus 作为时间序列数据库,Grafana 作为可视化平台。你也可以用 Grafite 代替 Prometheus,或者直接使用 Netdata 为 Grafana 开发的 Netdata 数据源插件,方便 Grafana 直接使用 Netdata 采集的数据。
在实际的生产中,我们使用 netdata 采集数据,并导出到 prometheus 中,使用 prometheus 充当数据库缓存时序数据(可替换为其他时序数据库,由于 influxdb 更新变更太大,放弃它了)。使用 grafana 抓取 prometheus 中时序数据进行可视化。
参考教程:
netdata 一般不会单独使用,大部分的时候是作为数据的收集端来收集指标数据
实践
这篇文章只作为 Netdata 的学习文档,把 netdata 的能力,写一个大纲,记录下来。其实主要用也就三个方面,指标采集,配置告警规则,对接通知系统,就这三个,另外再写一篇博客记录一下咋用的即可
再写一篇文章,简单实践 SpringBoot 项目的指标收集,简单实践 Java 项目的指标收集,告警信息配置,然后通知,TODO